
���l�I����3A���}�����^3A����ָ�W��������AEC, Acoustic Echo Cancel�������������ƣ�ANS, Automatic Noise Suppression�����Ԅ�������ƣ�AGC, Automatic Gain Control����������һ��AEC��

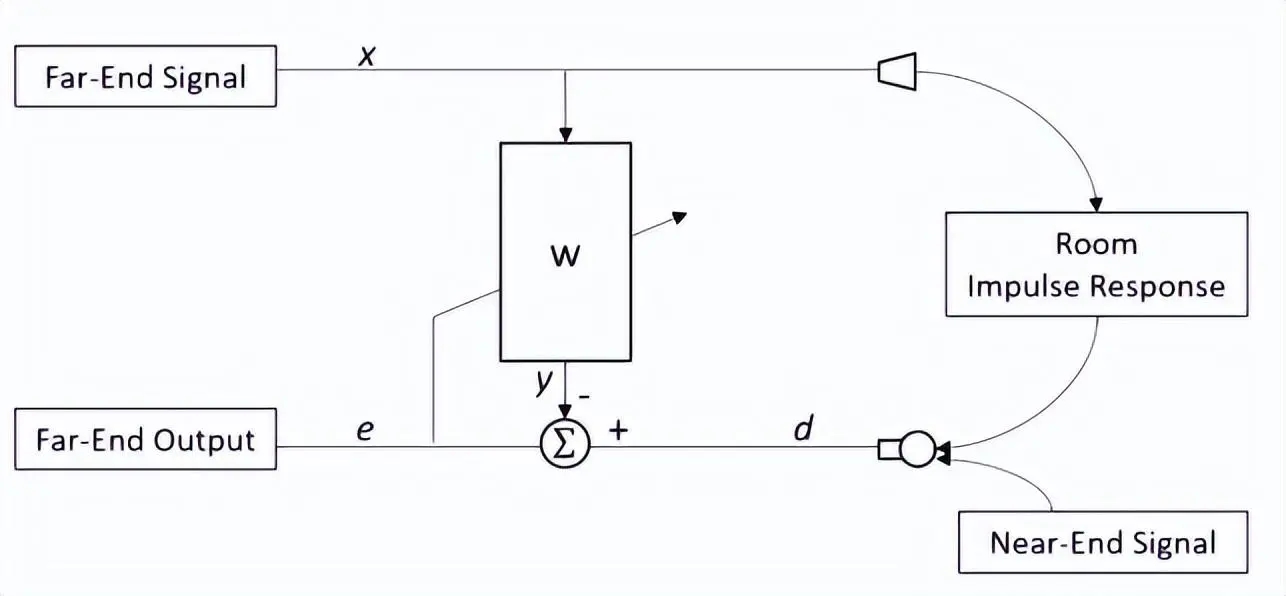
��ͨӍ�����a����ԭ�����Է֞��W������Acoustic Echo���;�·������Line Echo���������Ļ��������g�ͽ��W��������Acoustic Echo Cancellation��AEC���;�·��������Line Echo Cancellation, LEC���� �W������������������ߕ��h�����У��P��������η����������L����ģ���·����������������Ӿ�·�Ķ��ľ�ƥ���������ģ����vֻӑՓ�W�����������Ի���̖�ͷǾ��Ի���̖����
�h���vԒ�ߣ�A��������̖�ق�ݔ�o���ˣ�B�����ڽ����O��ēP�����ų��������^һϵ���W���䣬�������O��������Lʰȡ���ւ�ݔ�o�h�ˣ�A���ĬF���W���������h���vԒ��A�ںܶ̕r�g�ȣ��� �����Լ����ŵ��vԒ�����W���Įa���^����D��ʾ��
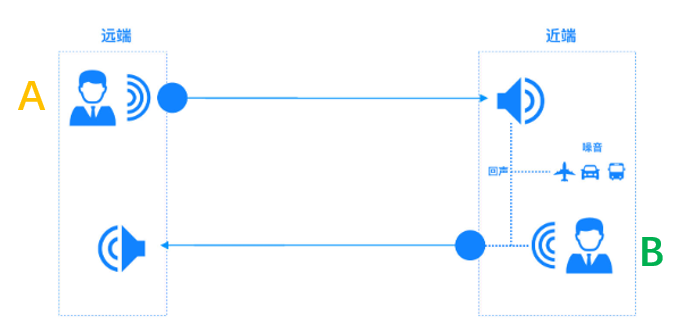
ʹ�� AEC ���g�ɶ����ݔ�^�̸�׃�����D��ʾ���M���ĵӱ��C���h���������ĸɃ��ȡ�
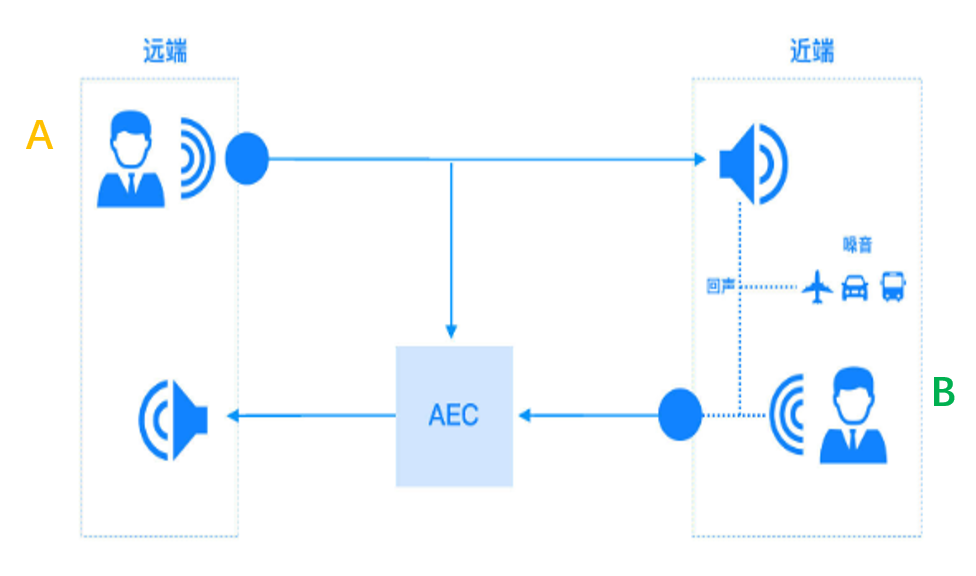
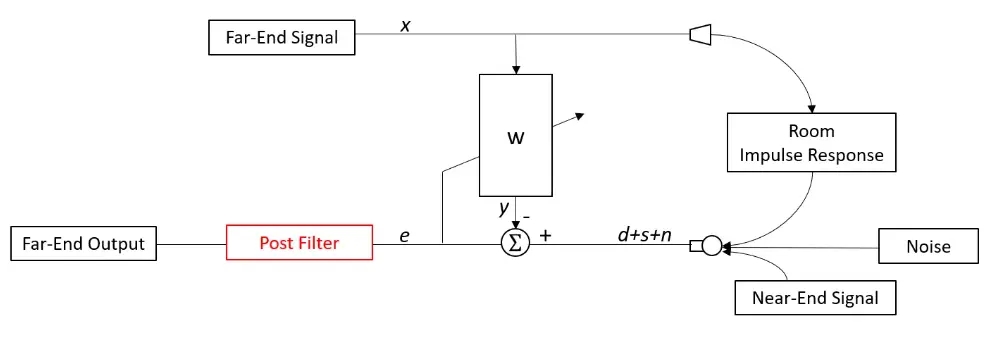
���W����ʾ���D��
�h����̖x, �� Ͳ������spk�����������^���g�������������Lmic���գ������fԒ��̖Ҳ�M�������Lmic���@�������L���յ��ľ��ǃɂ���̖�įB�ӣ���d�����m���V����w��x�M��̎���@��y������̖����d��y�IJ�ֵ�����`��e�����f�o���m���V�������M�ОV����ϵ���������¡�
ָ��1��ERLE(Echo Return Loss Enhancement��������˥�p����)��

ERLEֵԽ�t����������Ч��Խ�á������p�v��ֻ�н��ˆ��v�r��e(n)�а��������Z�������ºܶ���r��e(n)�������h���ڻ�y(n)���������Ķ�ERLE��ֵؓ��ͬ�rҲ�o�����������ֵ�������r��
���ڃ���Ļ���������ERLE�����횲�����6dB��
ָ��2��SupperFactor������˥�p���ӣ�
AEC��ݔ�������c�����h�������L��̖�����ı�ֵ��
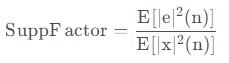
ָ��3��Cohde(ݔ����̖e(n)�c�����L��̖d(n)���l�V���P��)
ԓֵԽ�ӽ�1���f��ݔ����̖�б����������L��̖�l�VԽ�ࡣ���]�������L��̖d(n)��Ҫ�ɻ���̖y(n)�ͽ����Z��v(n)���ɣ����ֻ�н��ˆ��v��r��cohde��ֵ���ܽӽ�1���p�v��r��cohde��ֵ��0.5��0.9��ȡ�Q�ڻ���̖��ԓ����ռ�ȣ�����cohde�ӽ�0�r�f��ݔ����̖���������κν����Z���ͻ����l�V�ɷ֡���Ӌ�㹫ʽ���£�
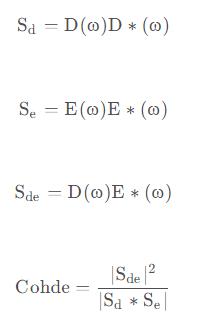
ָ��4��Cohxe(ݔ����̖e(n)�c�h�˅�����̖x(n)���l�V���P��)
ԓֵԽ�ӽ�0���f��ݔ����̖�К������h�˅�����̖�l�VԽ�٣�������Խ�صף���Ӌ�㹫ʽ���£�
��ͬͨԒ��B�����ą���ָ�ˣ�
��1�����ˆ��v�����̶ȱ���ݔ���c�����L��̖һ�£���
Cohde��Խ�ӽ�1�f��ݔ���c�����L��̖Խ���ƣ�Խ�ӽ�0�f�����߲Խ���ˆ��v�r����ֵ��1��
Cohxe��Խ�ӽ�1�f��ݔ���c�h�˅�����̖Խ���ƣ�Խ�ӽ�0�f�����߲Խ���������h�˅�����̖�l�V�ɷ�Խ�٣�����ֵ��0��
SuppFactor��Խ�ӽ�1�f��ݔ���c�����L��̖������Խ�ӽ���Խ�ӽ�0�f��AEC�������˥��Խ���أ����ˆ��v�r����ֵ��1��
��2���h�ˆ��v�����̶����ƻ�����
ERLE��ֵԽ��Խ�ã��t��������������������ֵԽС��������Ч��Խ�á�
Cohde��Խ�ӽ�1�f��ݔ���c�����L��̖Խ���ƣ�Խ�ӽ�0�f�����߲Խ���h�ˆ��v�r����ֵ��0��
Cohxe��Խ�ӽ�1�f��ݔ���c�h�˅�����̖Խ���ƣ�Խ�ӽ�0�f�����߲Խ���������h�˅�����̖�l�V�ɷ�Խ�٣�����ֵ��0��
SuppFactor��Խ�ӽ�1�f��ݔ���c�����L��̖������Խ�ӽ���Խ�ӽ�0�f��AEC�������˥��Խ���أ��h�ˆ��v�r����ֵ��0��
��3���p�v���M�����ƻ�ͬ�r���������Z����
Cohde��Խ�ӽ�1�f��ݔ���c�����L��̖Խ���ƣ������Ľ����Z���l�V�ɷ�ҲԽ�ࣻԽ�ӽ�0�f�����߲Խ�����Ľ����Z���l�V�ɷ�ҲԽ�٣��p�v�r����ֵ��0.5��0.9��ȡ�Q�ڻ���̖��ԓ����ռ�ȣ���
Cohxe��Խ�ӽ�1�f��ݔ���c�h�˅�����̖Խ���ƣ�Խ�ӽ�0�f�����߲Խ���������h�˅�����̖�l�V�ɷ�Խ�٣��p�v�r����ֵ��0��
SuppFactor��Խ�ӽ�1�f��ݔ���c�����L��̖������Խ�ӽ���Խ�ӽ�0�f��AEC�������˥��Խ���أ��p�v�r����ֵ��1��
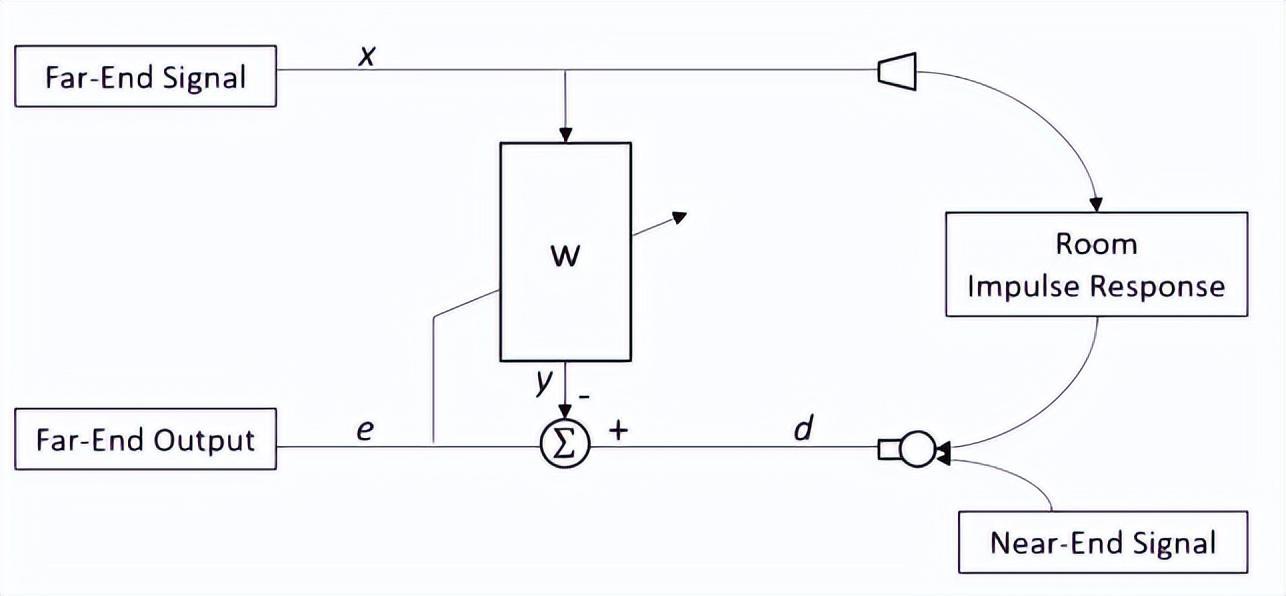
���ͻ��������g������D��
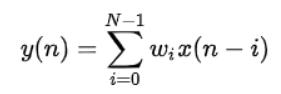
�h����̖x�� Ͳ������spk�����������^���g�������������Lmic���գ������fԒ��̖Ҳ�M�������Lmic���@�������L���յ��ľ��ǃɂ���̖�įB�ӣ���d�����m���V����w��x�M��̎���@��y������̖����d��y�IJ�ֵ�����`����f�o���m���V�������M�ОV����ϵ���������¡�
�h�˅�����̖���ψDfar-end signal�����^���m���V����w
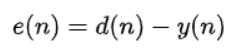
�h�˅�����̖���^���g�����������^Room Impulse Response���õ�x'
Ŀ���`��


�䌍�����m���V���������þ��ǁ��������g�_��푑���x��Ӱ푣����`����С��Ŀ�ˡ�
���w�㷨��
��1��LMS(least mean square)
LMS����V�����õ����m���V���㷨����MSE�`���Ŀ�˺��������ݶ��½��郞���㷨��NLMS��ʹ��ݔ��Ĺ��ʌ����L�M�Кwһ���ķ���������ȡ�ø��õ��Ք����ܡ�
�㷨���s��:
LMS: (2M+1�γ˷���2M�μӷ�) * �����L��
NLMS: (3M+1�γ˷���3M�μӷ�) * �����L��
��2��Block LMS
LMS�㷨��ݔ�딵���Ǵ���̎���ģ�����ͨ�^��ݔ�딵���ֶβ���̎���������ȌW���I���mini-batch����, ���������l��FFT�������پ��e�����p��Ӌ����s�ȡ�
������Ҫ�����е�LMS�㷨�D׃��։K̎����Ҳ����Block LMS(BLMS)�� ÿ�ε�����ݔ�딵�����ֳ��L�Ȟ�L�ĉK�M��̎������LMSʹ��˲�r�ݶȁ��M�ОV�����������²�ͬ��BLMSʹ��L�c��ƽ���ݶȁ��M�Ѕ������¡� ����k�K������BLMS�㷨�f�ƹ�ʽ�飺
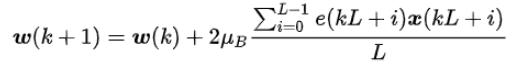
��3��Fast Block LMS
˼��������FFT�M���������٣��Q��Fast Block LMS����Frequency Domain Adaptive Filter�������L�Ȟ�M�ĞV������һ�����2M�c��FFT��M�c�a�㣩����ʹ��overlap-and-save�Ŀ��پ��e������



�㷨���s��: 10MlogM +26M
��4��Partitioned Fast Block LMS
���V�����ĕr�L�M�зָ�_�����͕r�ӵ�Ŀ�ġ��ַQMultidelay block filter(MDF)��
������L�Ȟ�M�ĞV�����ȷֳ��L�Ȟ�B��С�Σ�M=P*B���t���e�ĽY�����Էֽ�邀P���e�B�ӡ�
�����h����ͬ�r�vԒ������ᘌ�ԓ������Ҫ�M���p�v�z�顣
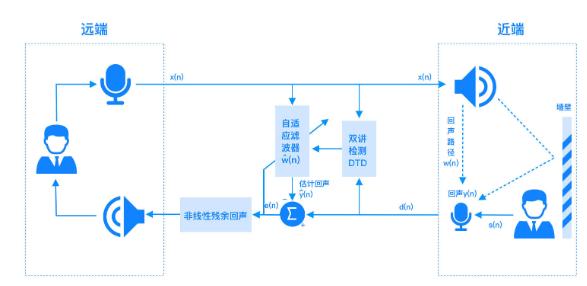
���m���V���������N����ģʽ��ͨ�^DTD�p�v�z�y����
�� �h���Z�����ڣ������Z�������ڣ��V�������m���V����ϵ������
�� �h���Z�����ڣ������Z�����ڣ��V��
�� �h���Z�������ڣ�ʲô��������

Webrtc�еĻ�����ģ�K���Ѱ������p�v�z�y���g���Z����әz�y���^��ϣ�D�����Ƿ�����p���vԒ�������m���V�����g����Ҫ����ָ�ˣ���ۙ���ܡ����_���ԡ������Ժ�Ӌ����s�ԣ�����̎�����������m���V������ݔ���`���
�p�V�����Y���c�p�v�z�y��
Speex ����ʹ��MDF�����m���V����߀�������p�V�����Y��(Two-Path Method)�� �p�V�����Y������һ���������µ����m��Background Filter, ��һ�������m����Foreground Filter�������m���V��������׃�ġ������lɢ�r�� AECʹ��Foreground Filter�ĽY������������Background Filter�� ��Background Filter ����׃�Õr�����䅢�����d��Foregound Filter��
�@�N�p�V�����Y�������Ԍ��F�[ʽ���p�v�z�y�� ���p�v����r�£�Background Filter�o���Ք�������½Y��������������Ҳ�͌��F�˅^���p�v�ͷ��p�v��Ŀ�ˡ�
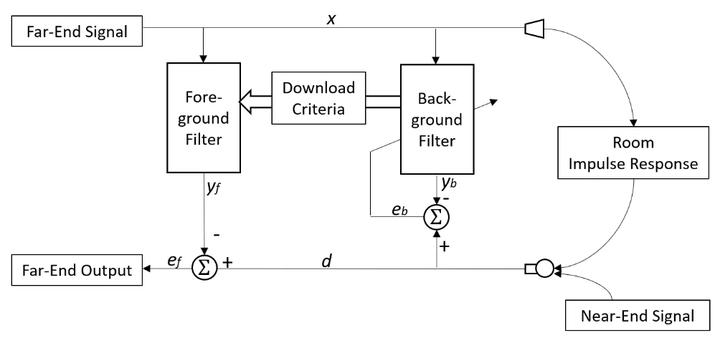
�ψD���ǵ��͵��p�V����AEC�Y��������ľ��nj�Background Filter���d��Foregound Filter���ЛQ�˜ʡ�һ����ԣ�������������Ŀ��]��

Speex AECʹ�õ��ЛQ�ʄt�����ԏĴ��a�����្�������������ᵽ�Ď��c����ȫһ�ӣ�����Foreground Filter��Background Filterݔ���Ě�������֮����M���Єe��
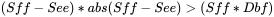
![]()
���� Sff ��Foreground Filter�c�����L��̖֮��Ĺ��ʣ� see ��Background Filter�c�����L��̖֮��Ĺ���, Dbf�ǃɂ�Filterݔ����̖֮���ƽ���� �����Єe��ʽ���Ԍ���
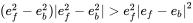
5. ���m���V�������L����
�����v��ĞV�������L�̶����䌍Ҳ���Ԍ����L���酢�����ѹ̶����L�����ɿ�׃���L������ͨ�^��ǰ�ĸ�����̖���ƌ�������L��
��Ҫ�ǻ���Փ��On Adjusting the Learning Rate in Frequency Domain Echo Cancellation With Double-Talk.
����ժ����е���Ҫ�YՓ�� ����L���ښ���������c�`����̖����֮��

����Ӌ�㚈�����Ĺ��ʣ����xй©���� U �� ȡֵ��0��1֮�g

й©����ͨ�^�f�wƽ�����£�
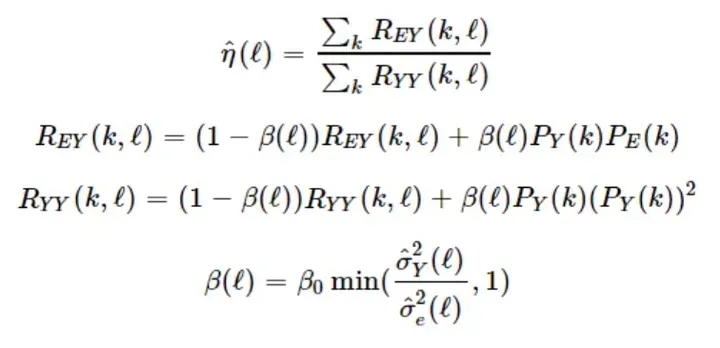
���m���V�������ܰٷְ���������AEC��ݔ����̖���К����Ļ���̖���@���r�����Ҫһ��Post-Filter���M�К�����������Residual Echo Cancellation�������Բ�����̖̎��������Ҳ���Բ�����ȌW��������
Contact
������S�a��������
